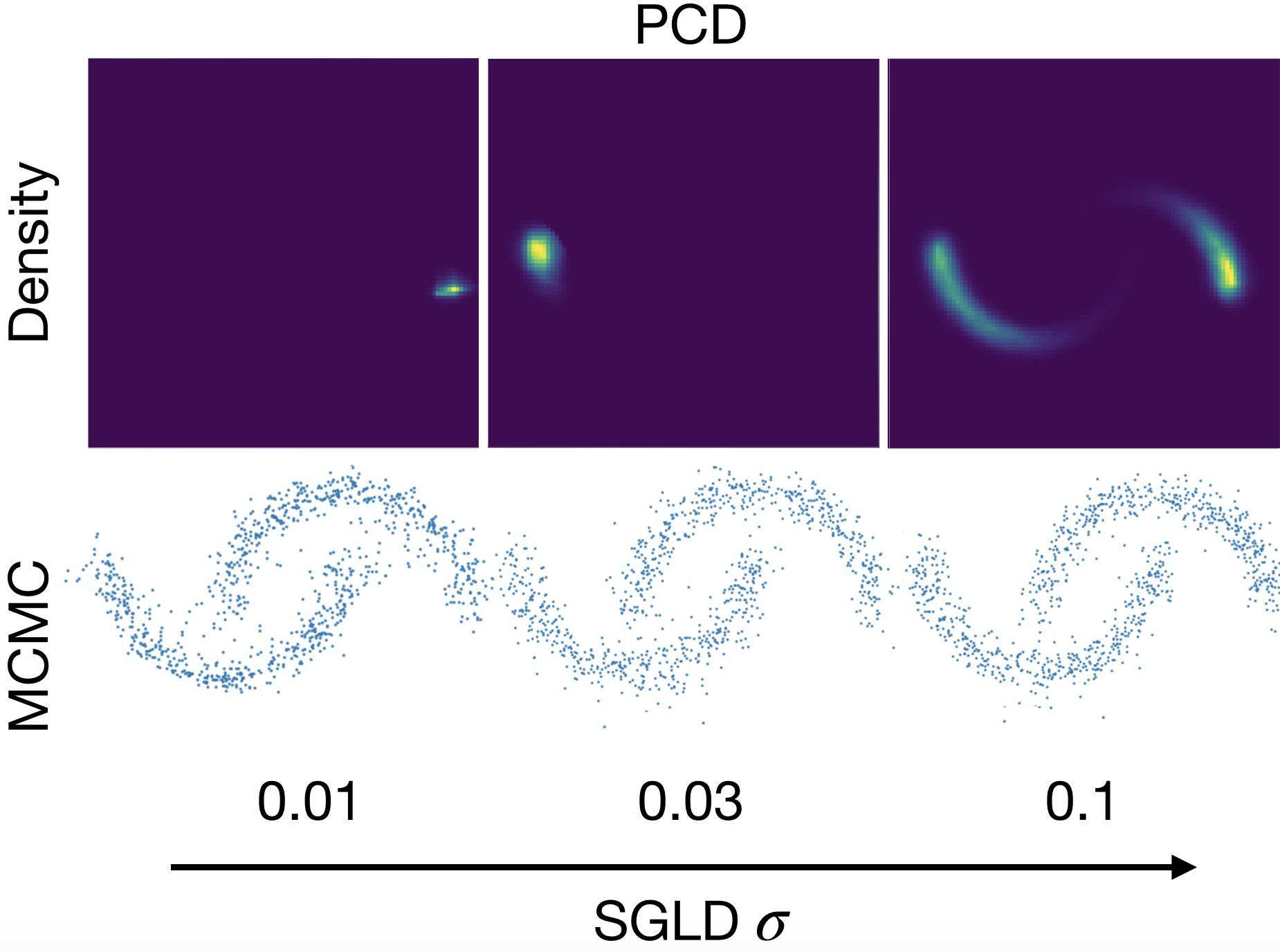
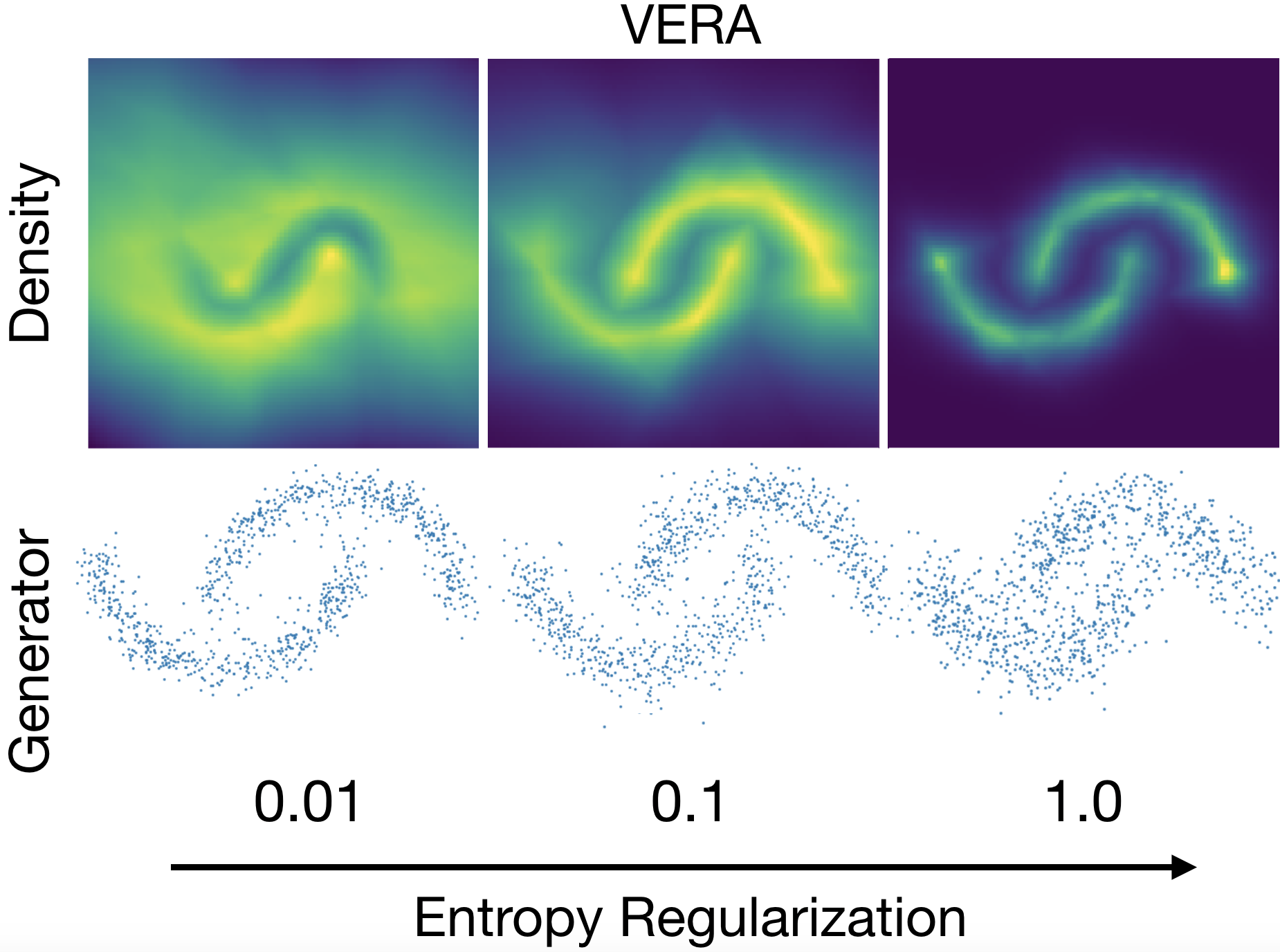
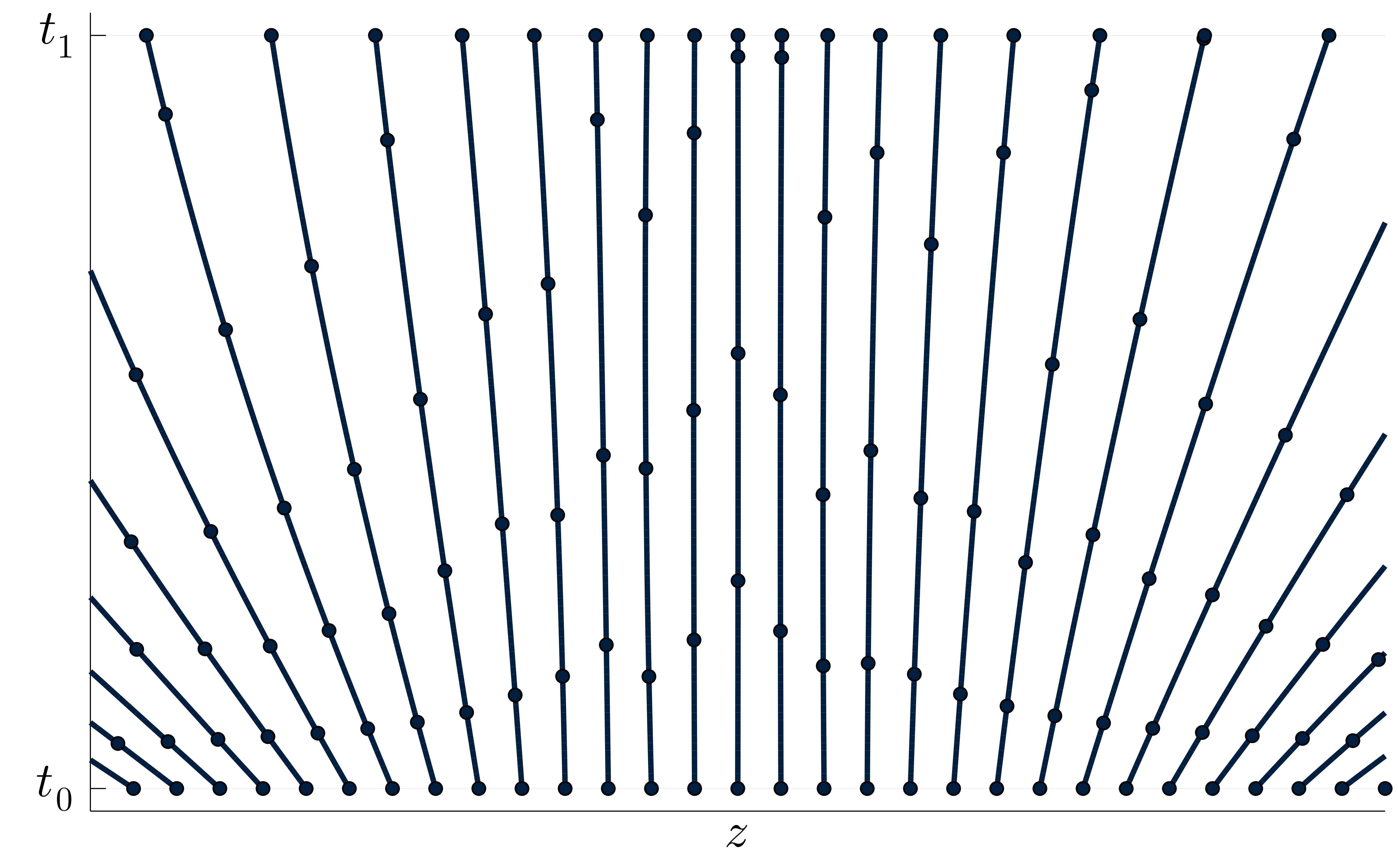
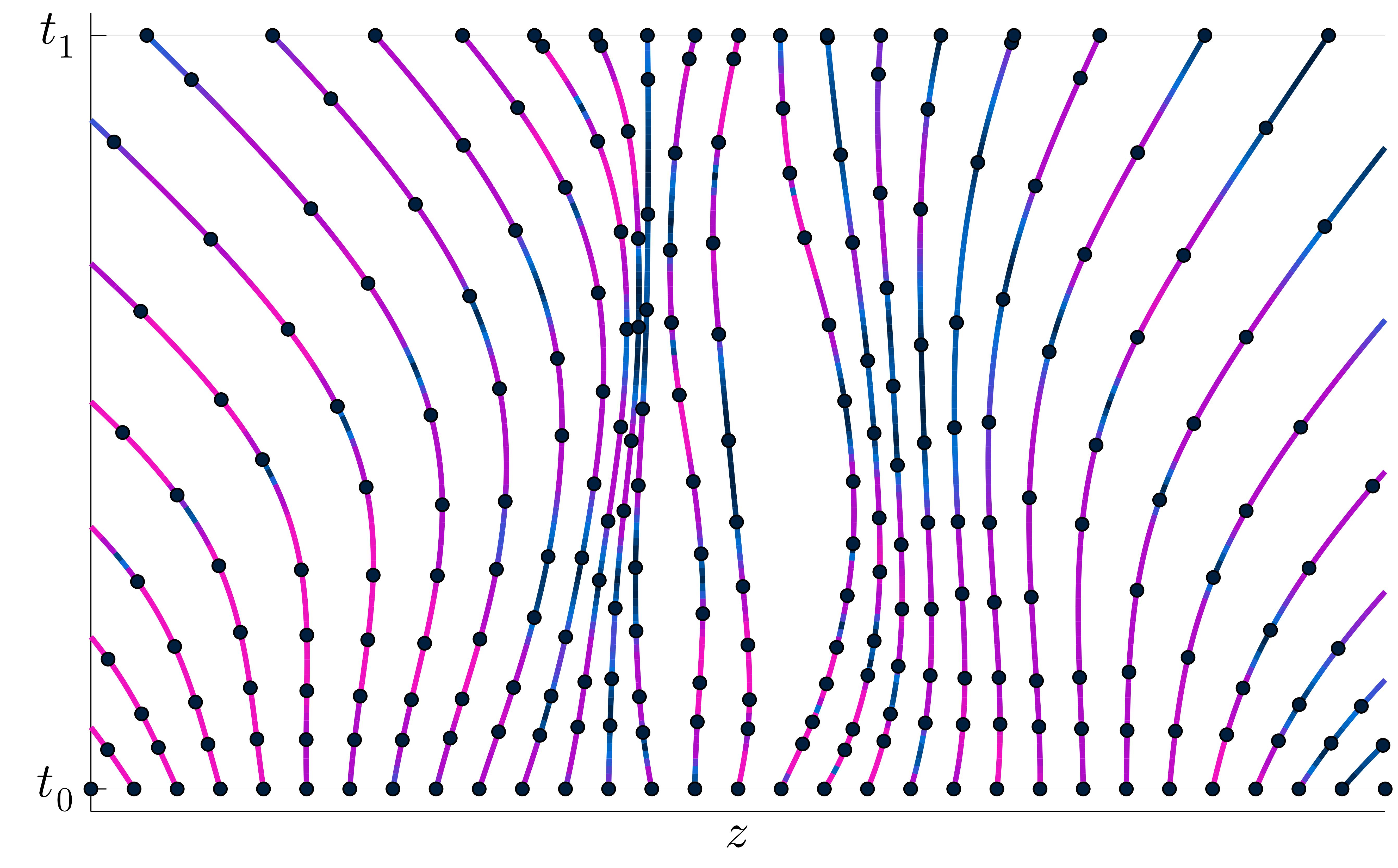
Jacob Kelly
I'm a Research Engineer at DeepMind.
I completed my undergrad in Computer Science, Math, and Stats at the
University of Toronto,
where I was fortunate to work with
Roger Grosse and
David Duvenaud
at the Vector Institute.
My goal is to use machine learning to understand biology.
I'm interested in energy-based models, latent variable models, neural ODEs, and genomics.
Previously, I was a Machine Learning Research Intern at
Deep Genomics.
Before that, I did computational biology research with
Benjamin Haibe-Kains
at the Princess Margaret Cancer Centre.
My hobbies include running, rock climbing, and reading.
Feel free to get in touch
if you'd like to chat.